Để hiểu Big Data (Dữ liệu lớn), trước tiên chúng ta cần biết Data (dữ liệu) là gì? Từ điển Oxford định nghĩa Data là:
"Số lượng, ký tự hoặc ký hiệu mà các hoạt động được thực hiện bởi máy tính, có thể được lưu trữ và truyền dưới dạng tín hiệu điện và được ghi trên phương tiện ghi từ tính, quang học hoặc cơ học."
Vậy, Big Data cũng là một dữ liệu nhưng có kích thước khổng lồ. Big Data là thuật ngữ được sử dụng để mô tả bộ sưu tập dữ liệu có kích thước khổng lồ và đang tăng lên với cấp số nhân theo thời gian.
Tóm lại, dữ liệu đó quá lớn và phức tạp đến nỗi không có công cụ quản lý dữ liệu truyền thống nào có thể lưu trữ hoặc xử lý nó hiệu quả.
Ví dụ về Big Data
Sau đây là một số ví dụ về Big Data

Ví dụ về Big Data - Dữ liệu thị trường chứng khoán Mỹ tạo ra
Sàn giao dịch chứng khoán New York tạo ra khoảng một terabyte dữ liệu giao dịch mới mỗi ngày.

Ví dụ về Big Data - Dữ liệu người dùng Upload lên Facebook
Theo thống kê cho thấy 500+ terabyte dữ liệu mới được đưa vào cơ sở dữ liệu của Facebook mỗi ngày. Dữ liệu này chủ yếu được tạo ra về mặt tải lên hình ảnh và video, trao đổi tin nhắn, comment, v.v.

Ví dụ về Big Data - Dữ liệu động cơ phản lực tạo ra
Động cơ phản lực đơn có thể tạo ra hơn 10 terabyte dữ liệu trong 30 phút sau một chuyến bay. Với nhiều nghìn chuyến bay mỗi ngày, việc tạo ra dữ liệu lên tới nhiều Petabyte.
Có những loại Big Data nào?
Big Data có thể được tìm thấy dưới ba dạng:
-
Structured
-
Un structtured
-
Semi-structure
Dữ liệu có cấu trúc (Structured)
Bất kỳ dữ liệu nào có thể được lưu trữ, truy cập và xử lý ở dạng định dạng cố định được gọi là dữ liệu 'có cấu trúc' (Structured Data).
Theo thời gian, với các thành tựu khoa học máy tính ngày càng cao hơn trong việc phát triển các kỹ thuật để làm việc với loại dữ liệu đó (trong đó định dạng được biết đến trước) và cũng nhận được giá trị từ nó.
Tuy nhiên, ngày nay, chúng ta đang thấy trước các vấn đề khi kích thước của dữ liệu đó tăng lên rất lớn, kích thước bắt đầu lên tới nhiều zettabyte
-
Bạn có biết? 10^21 byte tương đương với 1 zettabyte hoặc một tỷ terabyte sẽ tạo thành một zettabyte.
Nhìn vào những số liệu này, người ta có thể dễ dàng hiểu tại sao cái tên 'BIG DATA' được đưa ra và thử tưởng tượng những thách thức liên quan đến việc lưu trữ và xử lý dữ liệu này.
-
Dữ liệu được lưu trữ trong hệ thống quản lý cơ sở dữ liệu quan hệ là một ví dụ về dữ liệu 'có cấu trúc'.
Ví dụ về dữ liệu có cấu trúc:
Bảng 'Employee' trong cơ sở dữ liệu là một ví dụ về Dữ liệu có cấu trúc
 Ví dụ về Big Data - Dữ liệu có cấu trúc
Ví dụ về Big Data - Dữ liệu có cấu trúc
Dữ liệu phi cấu trúc (Unstructure Data)
Bất kỳ dữ liệu nào có dạng không xác định hoặc cấu trúc được phân loại là dữ liệu phi cấu trúc.
Ngoài kích thước khổng lồ, dữ liệu không có cấu trúc đặt ra nhiều thách thức về mặt xử lý để lấy giá trị từ nó.
Ví dụ điển hình của dữ liệu phi cấu trúc là: Nguồn dữ liệu không đồng nhất chứa kết hợp các tệp văn bản, hình ảnh, video v.v ...
Bây giờ, một tổ chức ngày nay có sẵn rất nhiều dữ liệu với họ nhưng thật không may họ không biết cách lấy ra giá trị từ đó dữ liệu này ở dạng thô hoặc định dạng không có cấu trúc.
Ví dụ về dữ liệu phi cấu trúc
Chúng ta hãy thử tìm kiếm từ khóa Hadoop Big Data trên Google Search, kết quả trả về như sau:
 Ví dụ về Big Data - Dữ liệu phi cấu trúc
Ví dụ về Big Data - Dữ liệu phi cấu trúc
Bạn cũng sẽ nhận ra ngay, kết quả trả về với các bài viết, liên kết, hình ảnh và cả video nữa. Vậy thì với dữ liệu về "hadoop big data" được tìm thấy đa dạng như vậy, khai thác chúng thành dữ liệu có giá trị rất khó.
Dữ liệu bán cấu trúc (Semi-Structure Data)
Dữ liệu bán cấu trúc có thể chứa cả các dạng dữ liệu được định dạng. Chúng ta có thể thấy dữ liệu bán cấu trúc như một cấu trúc được phân tầng nhưng thực tế nó không được xác định.
Dữ liệu bán cấu trúc là dữ liệu được biểu thị trong tệp XML.
Ví dụ về dữ liệu bán cấu trúc
Dữ liệu cá nhân được lưu trữ trong tệp XML
<rec><name>Prashant Rao</name><sex>Male</sex><age>35</age></rec>
<rec><name>Seema R.</name><sex>Female</sex><age>41</age></rec>
<rec><name>Satish Mane</name><sex>Male</sex><age>29</age></rec>
<rec><name>Subrato Roy</name><sex>Male</sex><age>26</age></rec>
<rec><name>Jeremiah J.</name><sex>Male</sex><age>35</age></rec>
Tăng trưởng dữ liệu qua các năm
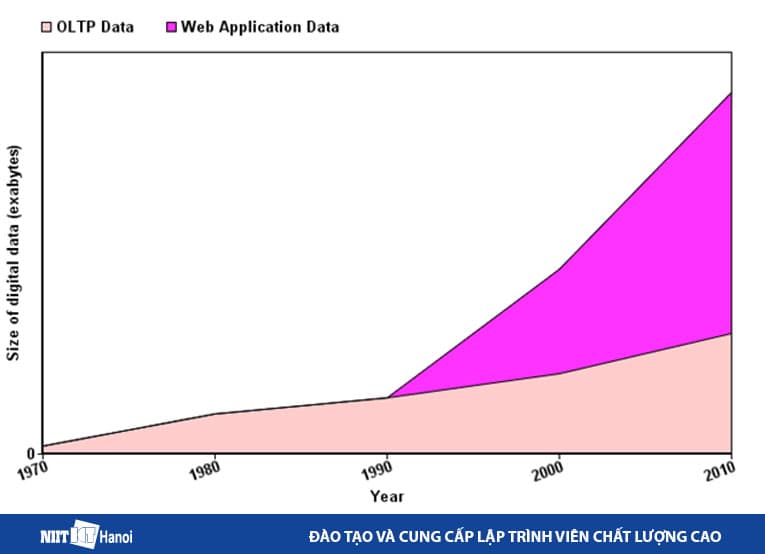 Biểu đồ tăng trưởng dữ liệu qua các năm
Biểu đồ tăng trưởng dữ liệu qua các năm
Xin lưu ý rằng dữ liệu ứng dụng web không có cấu trúc, bao gồm các tệp nhật ký, tệp lịch sử giao dịch, vv... Các hệ thống OLTP được xây dựng để làm việc với dữ liệu có cấu trúc trong đó dữ liệu được lưu trữ trong các mối quan hệ (bảng)
Đặc điểm của BIG DATA
Chúng ta có thể hiểu về dữ liệu lớn qua 4V: Volume, Variety, Velocity, Variability
1. Volume: Khối lượng của dữ liệu
Cái tên "Big Data" đã có liên quan đến kích thước rất lớn. Kích thước của dữ liệu đóng vai trò rất quan trọng trong việc xác định giá trị của dữ liệu.
Ngoài ra, việc một dữ liệu cụ thể có thực sự được coi là Dữ liệu lớn hay không, phụ thuộc vào khối lượng dữ liệu. Do đó, 'Khối lượng' là một đặc điểm cần được xem xét khi xử lý 'Big Data'.
2. Variety: Sự đa dạng của dữ liệu
Sự đa dạng nói đến việc các nguồn dữ liệu không đồng nhất và bản chất, cả có cấu trúc và phi cấu trúc.
Trước đây, bảng tính và cơ sở dữ liệu là nguồn dữ liệu duy nhất được xem xét bởi hầu hết các ứng dụng.
Ngày nay, dữ liệu dưới dạng email, ảnh, video, thiết bị giám sát, PDF, âm thanh, v.v. cũng đang được xem xét trong các ứng dụng phân tích.
Sự đa dạng của dữ liệu phi cấu trúc này đặt ra một số vấn đề nhất định cho việc lưu trữ, khai thác (mining) và phân tích dữ liệu (Analysing Data).
3. Velocity: Tốc độ tạo ra dữ liệu vô cùng nhanh.
Dữ liệu được tạo và xử lý nhanh như thế nào để đáp ứng nhu cầu, xác định tiềm năng thực sự trong dữ liệu.
4. Variability: Dữ liệu đôi khi không nhất quản do đó cản trở quá trình xử lý và quản lý dữ liệu hiệu quả.
05 Lợi ích của xử lý dữ liệu lớn
Khả năng xử lý 'Dữ liệu lớn' mang lại nhiều lợi ích, chẳng hạn như:
Lợi ích 1. Doanh nghiệp có thể phân tích dữ liệu để đưa ra quyết định đúng đắn
Truy cập dữ liệu xã hội từ các công cụ tìm kiếm và các trang web như facebook, twitter đang cho phép các tổ chức điều chỉnh chiến lược kinh doanh của họ phù hợp với nhiều người hơn.
Lợi ích 2. Dịch vụ khách hàng được cải thiện
Các hệ thống phản hồi khách hàng truyền thống đang được thay thế bằng các hệ thống mới được thiết kế với công nghệ 'Big Data'.
Trong các hệ thống mới này, Big Data và công nghệ xử lý ngôn ngữ tự nhiên đang được sử dụng để đọc và đánh giá phản hồi của người tiêu dùng.
Lợi ích 3. Xác định sớm rủi ro đối với sản phẩm / dịch vụ, nếu có
Lợi ích 4. Hoạt động kinh doanh hiệu quả hơn
Công nghệ 'Big Data' có thể được sử dụng để tạo khu vực tổ chức hoặc khu vực hạ cánh cho dữ liệu mới trước khi xác định dữ liệu nào sẽ được chuyển đến kho dữ liệu.
Ngoài ra, việc tích hợp Data Warehouse và Big Data giúp tổ chức giảm tải dữ liệu truy cập không thường xuyên.
>>> Nếu doanh nghiệp bạn đang muốn phát triển kinh doanh hơn nữa nhờ Big Data thì hãy đăng ký ngay khóa đào tạo Big Data with Hadoop and Spark dành cho doanh nghiệp của NIIT - ICT Hà Nội.
Tổng kết
Như vậy là bạn đã hiểu qua về Big Data là gì, đặc điểm của Big Data và các lợi ích khi sử dụng Big Data. Bài tiếp theo chúng ta sẽ bắt đầu tìm hiểu về Hadoop.