Multi Node Cluster trong Hadoop 2.x
Từ bài trước trong series Marter BigData, chúng ta đã học cách thiết lập Sigle Node Cluster trong Hadoop.
Bây giờ, mình sẽ chỉ cho bạn cách thiết lập Multi Node Cluster trong Hadoop.
Một Multi Node Cluster trong Hadoop chứa hai hoặc nhiều DataNode trong môi trường Hadoop phân tán.
Điều này thực tế được sử dụng trong các tổ chức để lưu trữ và phân tích dữ liệu Petabyte và Exabyte của họ. Học cách thiết lập Multi Node Cluster giúp bạn tiến gần hơn đến việc làm chủ Hadoop.
Ở đây, chúng ta sẽ dùng hai máy - Chính và Phụ. Trên cả hai máy, một Datanode sẽ được chạy.
Chúng ta hãy bắt đầu với việc thiết lập Multi Node Cluster trong Hadoop.
Điều kiện tiên quyết trước khi thiết lập Multi Node Cluster
-
Cent OS 6.5
-
Hadoop-2.7.3
-
JAVA 8
-
SSH
Hướng dẫn 23 Bước Thiết lập Multi Node Cluster trong Hadoop
Chúng ta có hai máy (Chính và Phụ) với IP như sau:
-
Chính: 192.168.56.102
-
Phụ: 192.168.56.103
BƯỚC 1: Check địa chỉ IP của tất cả các máy
Sử dụng lệnh bên dưới trong Command
Command: ip addr show (bạn cũng có thể sử dụng lệnh ifconfig)
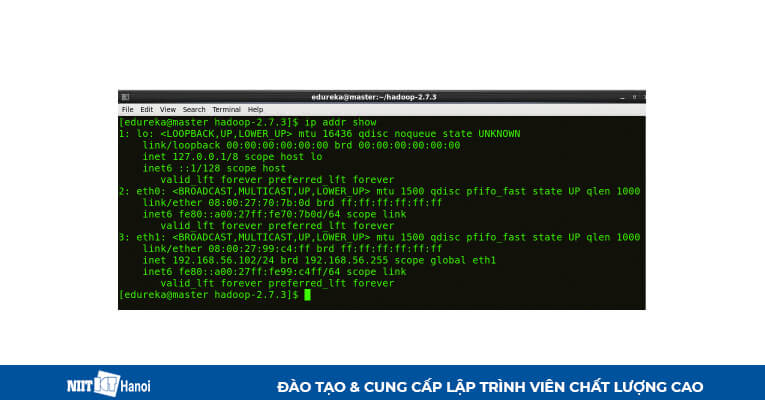
Check IP máy chính
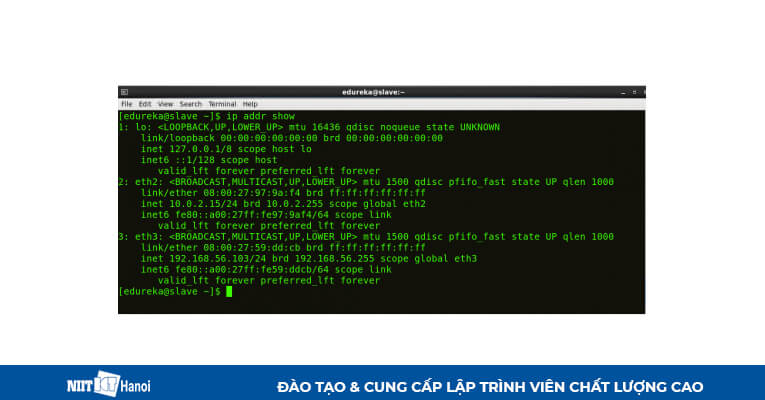
Check IP máy phụ
BƯỚC 2: Vô hiệu hóa tường lửa
Sử dụng lệnh sau trong Command
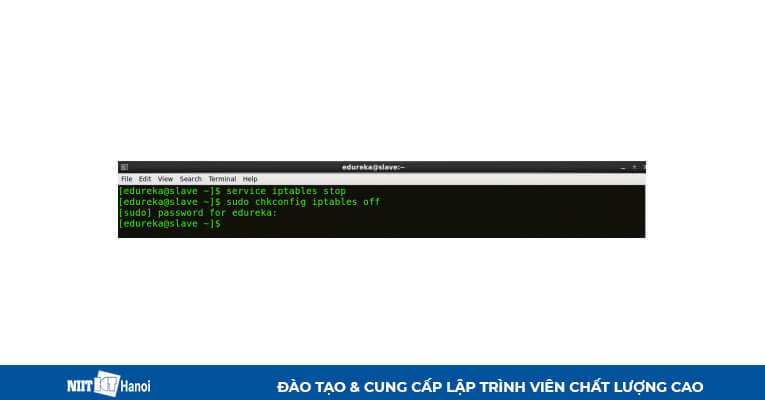 Vô hiệu hóa tường lửa
Vô hiệu hóa tường lửa
BƯỚC 3: Mở file hosts để thêm Master node và Data node với địa chỉ IP tương ứng của chúng
Các thuộc tính tương tự sẽ được hiển thị trong các tệp máy chủ chính và phụ.
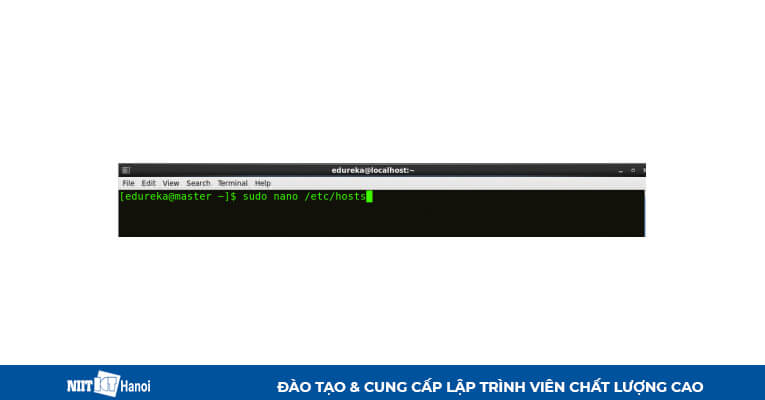
Mở file host và thêm data node với địa chỉ IP tương ứng
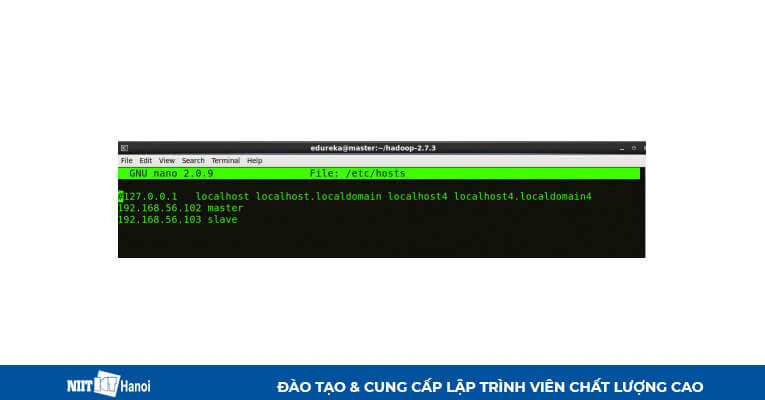
Đã thêm địa chỉ IP tương ứng
BƯỚC 4: Khởi động lại sshd service.
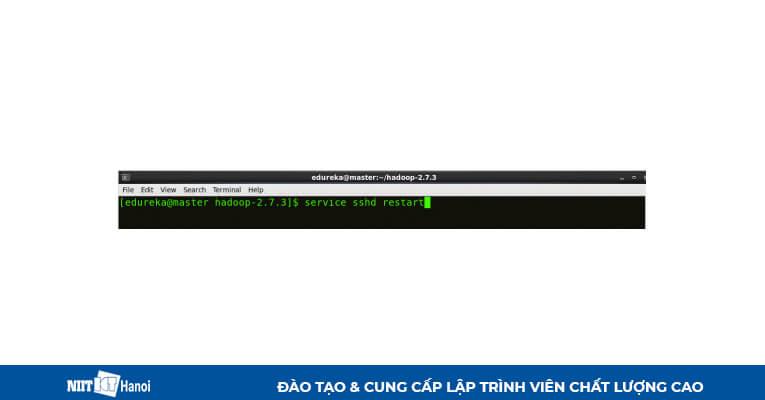
Khởi động lại ssh service
BƯỚC 5: Tạo SSH key trong Node chính. (Nhấn nút enter khi nó yêu cầu bạn nhập tên tệp để lưu key).
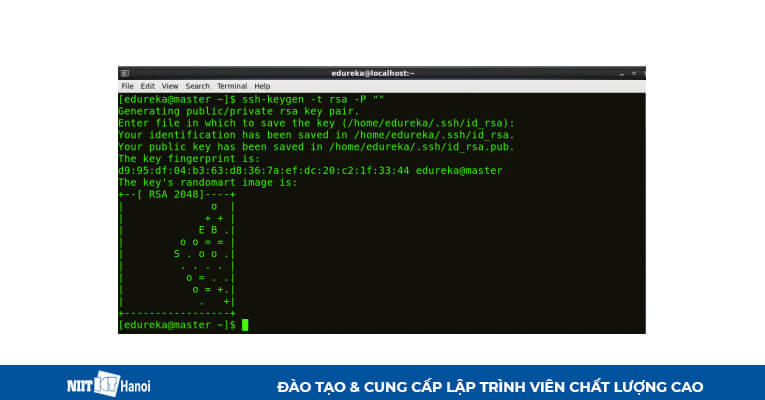 Tạo SSH key trong node chính
Tạo SSH key trong node chính
BƯỚC 6: Sao chép ssh key được tạo để làm authorized key của Node chính.
 Sao chép ssh key được tạo vào node chính
Sao chép ssh key được tạo vào node chính
BƯỚC 7: Sao chép key ssh node chính sang authorized key của node phụ.
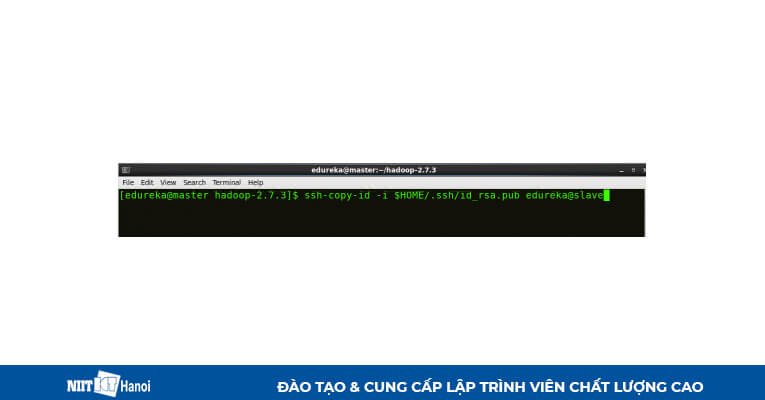 Sao chép ssh key được tạo vào node phụ
Sao chép ssh key được tạo vào node phụ
BƯỚC 8: Tải xuống Java 8 package. Lưu tập tin này trong thư mục home.
BƯỚC 9: Extra file Java Tar trên tất cả các node
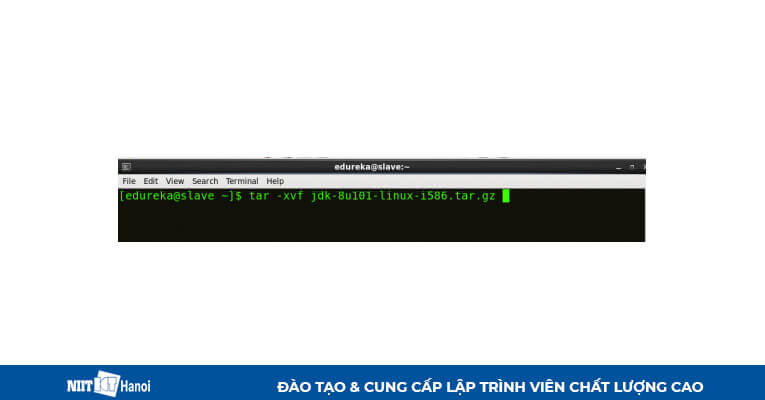 Giải nén file Java Tar
Giải nén file Java Tar
BƯỚC 11: Tải xuống Hadoop 2.7.3 package trên tất cả các node.
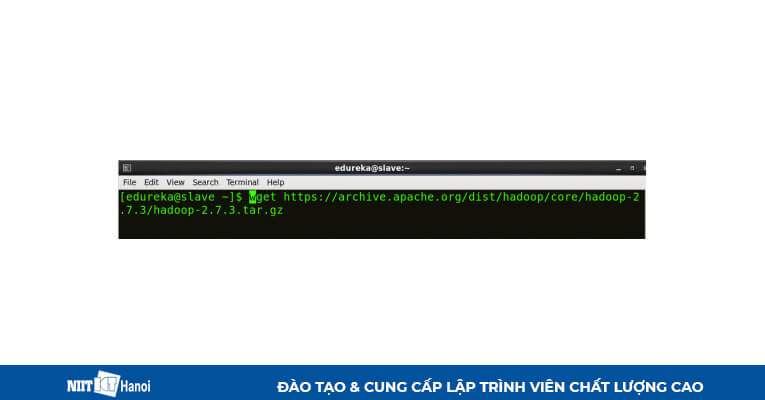 Tải xuống Hadoop
Tải xuống Hadoop
BƯỚC 11: Giải nén tệp Hadoop tar trên tất cả các node.
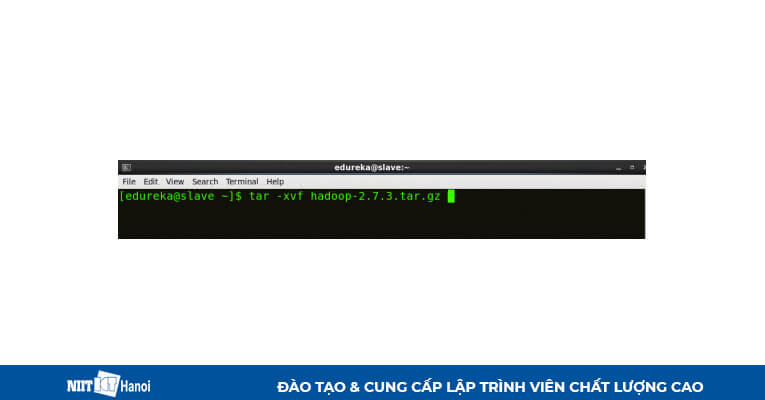 Giải nén file Hadoop tar
Giải nén file Hadoop tar
BƯỚC 12: Thêm các đường dẫn Hadoop và Java trong tệp bash (.bashrc) trên tất cả các node.
Mở tập tin bashrc. Bây giờ, thêm Đường dẫn Hadoop và Java như dưới đây:
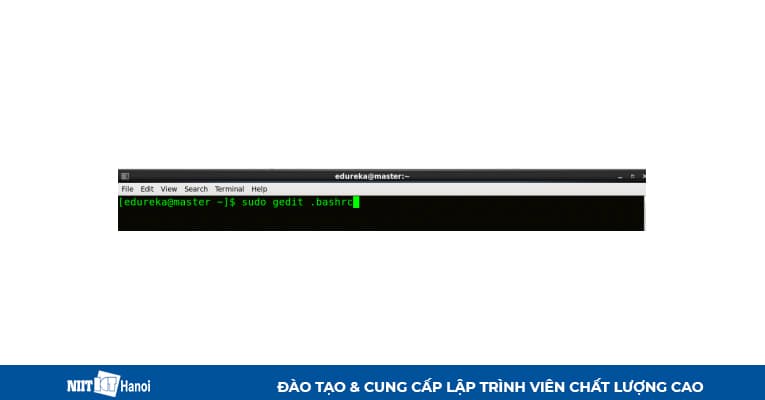 Mở file bashrc
Mở file bashrc
 Chỉnh sửa đường dẫn Hadoop và Java
Chỉnh sửa đường dẫn Hadoop và Java
Sau đó, lưu tệp bash và đóng nó lại.
Để áp dụng tất cả các thay đổi này cho Terminal hiện tại, hãy thực thi lệnh:
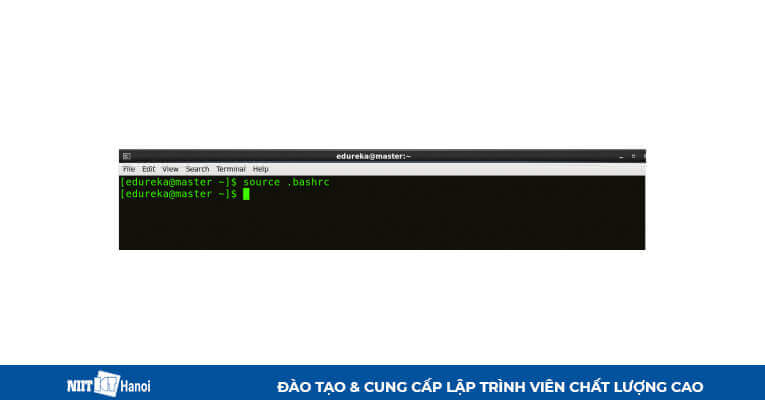 Thực thi lệnh source .bashrc
Thực thi lệnh source .bashrc
Để đảm bảo rằng Java và Hadoop đã được cài đặt đúng trên hệ thống của bạn và có thể được truy cập thông qua Terminal, hãy thực thi các lệnh java -version và hadoop version.
Bây giờ, hãy chỉnh sửa các tập tin cấu hình trong thư mục hadoop-2.7.3/etc/hadoop.
BƯỚC 13: Tạo file masters và chỉnh sửa như sau trong cả máy chính và máy phụ như sau:
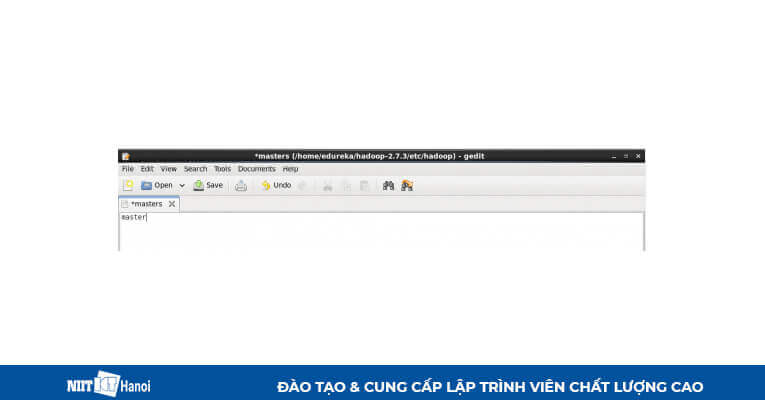 Chỉnh sửa file masters
Chỉnh sửa file masters
BƯỚC 14: Chỉnh sửa file slaves trong máy chủ như sau:
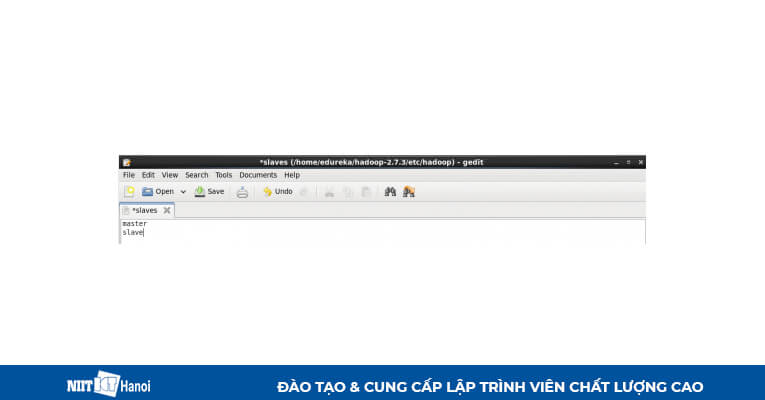 Chỉnh sửa file slaves trong máy Chính
Chỉnh sửa file slaves trong máy Chính
BƯỚC 15: Chỉnh sửa file slaves trong máy phụ như sau:
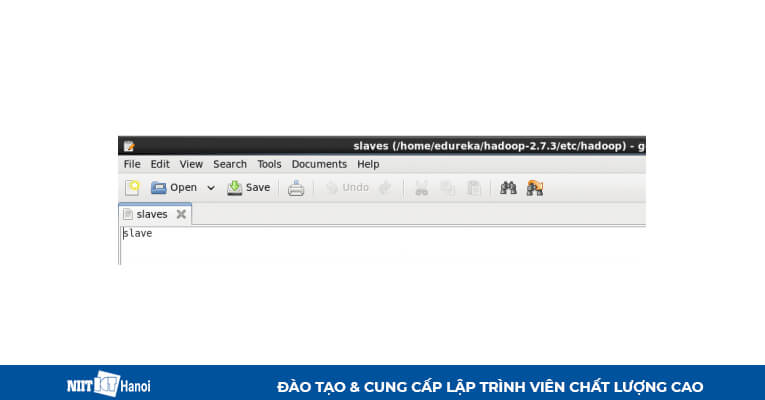 Chỉnh sửa file slaves trong máy phụ
Chỉnh sửa file slaves trong máy phụ
BƯỚC 16: Chỉnh sửa core-site.xml trên cả máy chính và máy phụ như sau:
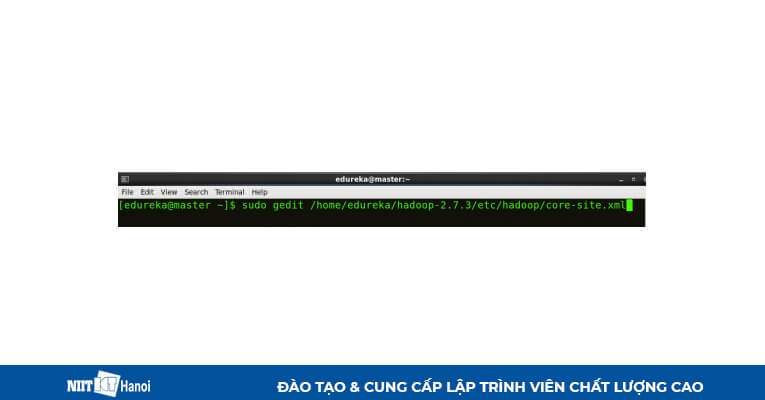 Chỉnh sửa core-site
Chỉnh sửa core-site
BƯỚC 7: Chỉnh sửa hdfs-site.xml trên master như sau:
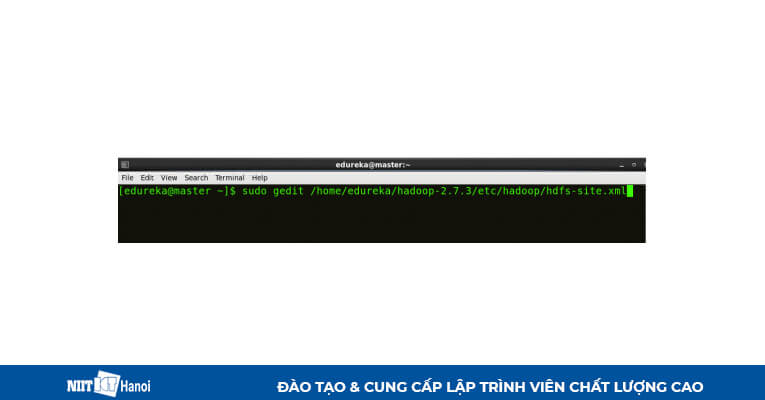 Chỉnh sửa hdfs-site
Chỉnh sửa hdfs-site
BƯỚC 18: Chỉnh sửa hdfs-site.xml trên máy phụ như sau
BƯỚC 19: Sao chép mapred-site từ mẫu trong thư mục configuration và chỉnh sửa mapred-site.xml trên cả máy chủ và máy phụ như sau:
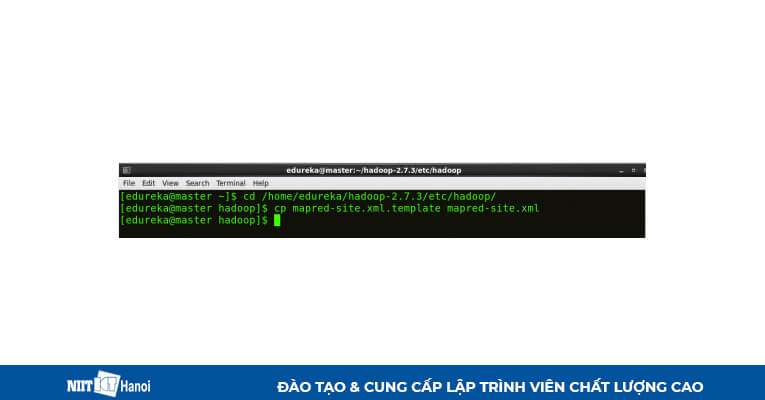 Sao chép và chỉnh sửa mapred-site
Sao chép và chỉnh sửa mapred-site
BƯỚC 20: Chỉnh sửa yarn-site.xml trên cả máy chủ và máy phụ như sau
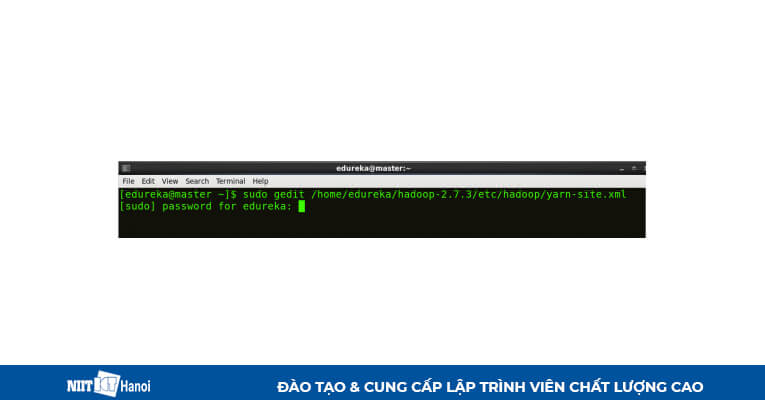 Sao chép và chỉnh sửa yarn-site
Sao chép và chỉnh sửa yarn-site
BƯỚC 21: Định dạng tên node (Chỉ trên máy chủ).
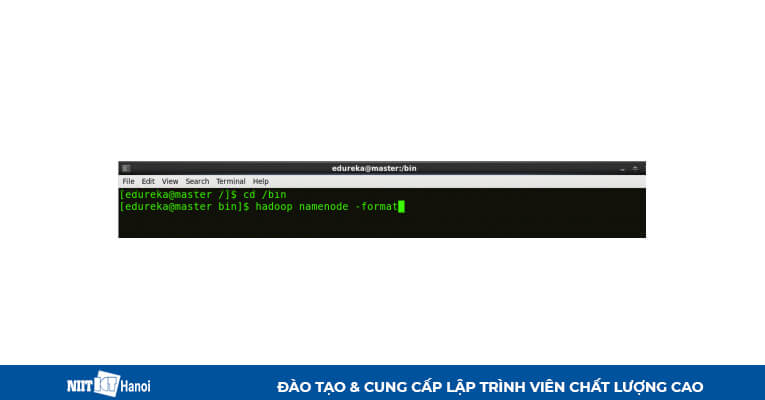 Chỉnh sửa namenode
Chỉnh sửa namenode
BƯỚC 22: Start all daemons (Chỉ trên máy chủ).
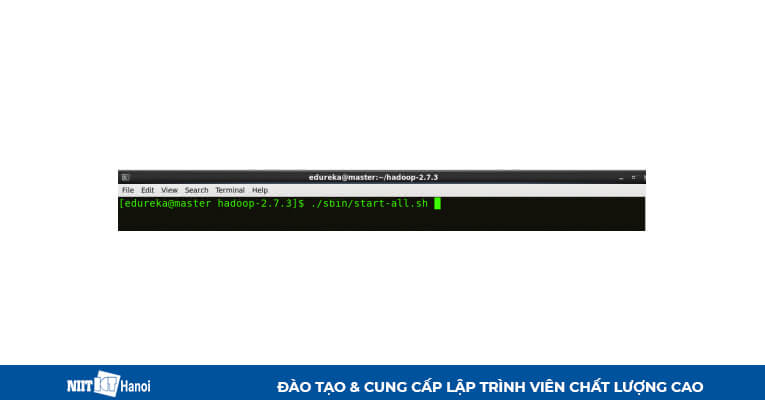 Start all daemons
Start all daemons
BƯỚC 23: Kiểm tra tất cả các trình tiện ích chạy trên cả máy chính và máy phụ
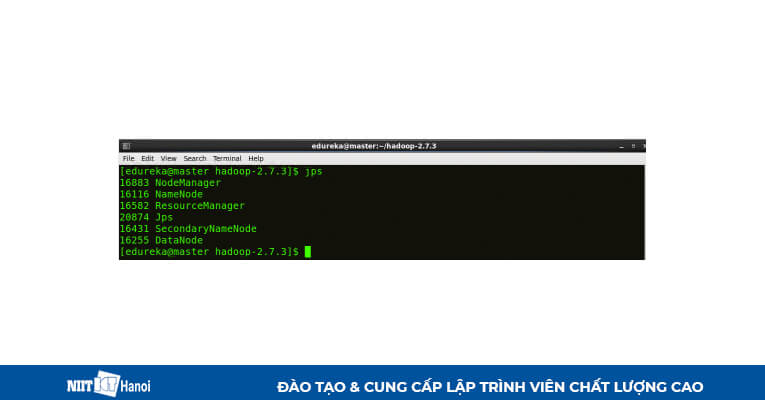
Kiểm tra trên máy chính
 Kiểm tra trên máy phụ
Kiểm tra trên máy phụ
Cuối cùng, hãy mở trình duyệt và truy cập theo đường dẫn master:50070/dfshealth.html trên máy chủ của bạn, nó sẽ đưa bạn đến giao diện NameNode.
Cuộn xuống và xem số lượng live node, nếu là 2, bạn đã thiết lập thành công cụm Hadoop đa node.
Trong trường hợp, nó không phải là 2, bạn có thể đã làm thiếu bước nào đó mà mình đã hướng dẫn ở trên.
Nhưng không cần phải lo lắng, bạn có thể quay lại và xác minh lại các bước từ đầu.

Cài đặt Multi Node Cluster trong Hadoop: Kết quả
Ở đây, chúng tôi chỉ có 2 DataNodes. Nếu bạn muốn, bạn có thể thêm nhiều DataNodes theo nhu cầu của mình.
Mình hy vọng bạn đã cài đặt thành công Cụm đa node trong Hadoop. Nếu bạn đang gặp phải bất kỳ vấn đề nào, bạn có thể bình luận bên dưới, mình sẽ cố gắng trả lời ngay.
>>> Nếu bạn muốn được hướng dẫn đầy đủ cho team của mình. Hãy đăng ký khóa Đào tạo Big Data để được hỗ trợ đầy đủ nhất.