Những xu hướng mới nhất trong phân tích Big Data
Bạn sẽ ngạc nhiên khi biết rằng lượng dữ liệu mà chúng ta tạo ra trong vòng 2 ngày nhiều hơn cả trong vòng một thập kỉ cộng lại. Quả là vậy, khi phần lớn chúng ta còn không nhận ra rằng mình đã tạo ra một lượng dữ liệu khổng lồ như vậy chỉ bằng cách truy cập vào internet.
Và nếu bạn không muốn tụt hậu trước những công nghệ của tường lai, hãy chú ý đến những xu hướng mới nhất trong lĩnh vực phân tích Big data và gặt hái thành công!
1.Dữ liệu dưới dạng dịch vụ (Data as a service - DaaS)
.jpg)
Thông thường dữ liệu được lưu trữ trong các kho dữ liệu, được lập trình để cung cấp dữ liệu cho các ứng dụng. Khi SaaS (phần mềm dưới dạng dịch vụ) đang còn phổ biến, Daas mới chỉ đang ở bước khởi đầu.
Bằng các ứng dụng Phần mềm dưới dạng dịch vụ, Dữ liệu dưới dạng dịch vụ sử dụng công nghệ đám mây để cung cấp theo yêu cầu của người dùng và các ứng dụng quyền truy cập vào thông tin mà không phụ thuộc vào việc người dùng hay ứng dụng đó ở đâu.
Dữ liệu dưới dạng dịch vụ là một xu hướng mới trong Phân tích Big data hiện nay và sẽ tiếp tục cung cấp các giải pháp đơn giản hơn cho các nhà phân tích để thu thập dữ liệu cho các công việc phân tích kinh doanh và giúp các bộ phận trong các doanh nghiệp hay trong các ngành công nghiệp dễ dàng chia sẻ dữ liệu với nhau .
2. Trí tuệ nhân tạo (AI) đáng tin cậy và thông minh hơn

AI đáng tin cậy và có khả năng mở rộng cho phép thực hiện các thuật toán học tập tốt hơn và từ đó tiết kiệm thời gian cho thị trường.
Các doanh nghiệp có thể đạt được nhiều thành quả hơn với các hệ thống AI ví dụ như xây dựng các quy trình xử lý hiệu quả. Các doanh nghiệp sẽ còn nỗ lực phát triển AI, và đó vẫn là một thách thức từ trước đến nay..
3. Phân tích dự đoán
Phân tích Big data vẫn luôn là giảp pháp cốt lõi để các doanh nghiệp giữ vững khả năng cạnh tranh và đạt được mục tiêu. Họ sử dụng các công cụ phân tích cơ bản để chuẩn bị dữ liệu và xác định được tại sao một vấn đề lại có thể phát sinh.
Các phương pháp dự đoán được thực hiện để nghiên cứu các dữ liệu mới và các sự kiện trong quá khứ để thấu hiểu khách hàng và nhận biết các nguy cơ và các sự kiện có thể xảy ra đối với doanh nghiệp. Phân tích dự đoán trong big data có thể dự đoán những gì có thể xảy ra trong tương lai.
Chiến lược này rất hiệu quả để chỉnh sửa lại các dữ liệu đã được tổng hợp và phân tích để dự đoán phản hồi của khách hàng. Điều này giúp các tổ chức có thể điều chỉnh lại hoạt động bằng cách xác định các hành động của khách hàng trước khi chúng xảy ra.
4. Điện toán lượng tử (Quantum Computing)

Sử dụng các công nghệ hiện tại để xử lý một lượng lớn dữ liệu có thể tốn rất nhiều thời gian. Trong khi các máy vi tính lượng tử có thể tính toán xác suất trạng thái của đối tượng hay một sự kiện trước cả khi nó được đo đạc, điều đó chỉ ra rằng nó có thể xử lý nhiều dữ liệu hơn các máy vi tính truyền thống.
Nếu có thể nén được hàng tỉ dữ liệu cùng lúc chỉ trong vòng vài phút, chúng ta có thể giảm thời gian xử lý đi rất nhiều, giúp các tổ chức, doanh nghiệp đưa ra các quyết định đúng lúc và đạt kết quả như mong muốn.
Phương pháp này có thể được hiện thực hóa nhờ có các máy vi tính lượng tử. Thử nghiệm các máy vi tính lượng tử để chỉnh sửa các nghiên cứu về cơ năng và phân tích có thể giúp các doanh nghiệp tính toán hoạt động một cách chuẩn xác hơn.
5. Điện toán biên (Edge Computing)
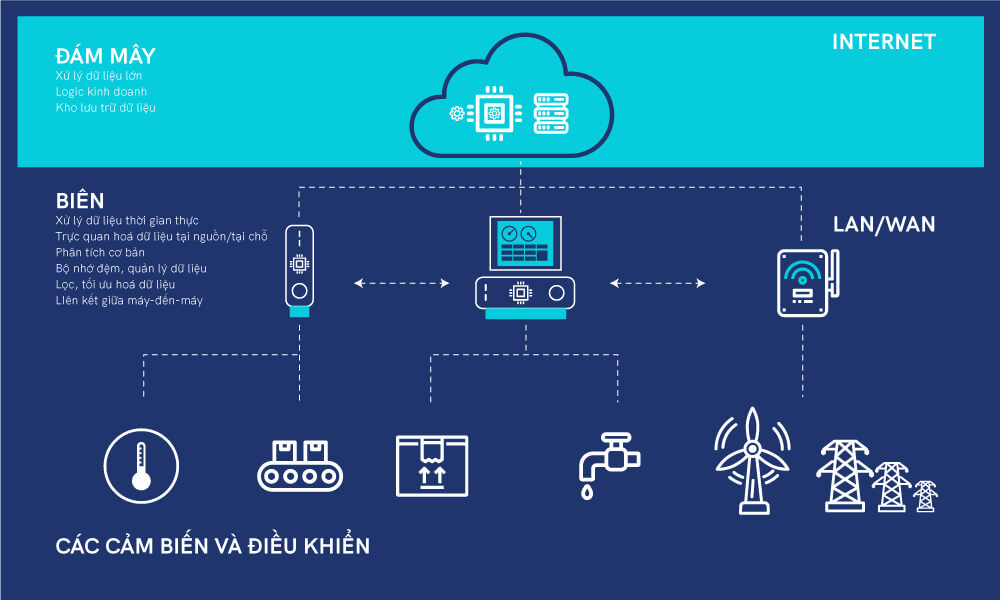
Chạy các quy trình và chuyển chúng đến một hệ thống cục bộ ví dụ như hệ thống máy tính của người dùng, một thiết bị IoT hay một máy chủ chính là định nghĩa của quy trình xử lý biên.
Điện toán biên chuyển các phép toán đến rìa của hệ thống mạng và giảm thiểu các kết nối khoảng cách xa giữa khách hàng và máy chủ, và nó đang trở thành xu thế lớn trong phân tích big data. Nó giúp tăng tốc độ truyền trực tiếp dữ liệu, bao gồm cả truyền trực tiếp dữ liệu theo thời gian thực và xử lý dữ liệu mà không có độ trễ, giúp các thiết bị có thể phản hồi ngay lập tức.
Điện toán biên là phương pháp hiệu quả để có thể xử lý lượng dữ liệu khổng lồ mà sử dụng ít băng thông hơn. Điều này giúp các doanh nghiệp có thể giảm thiểu chi phí phát triển, các phần mềm có thể chạy ở những nơi xa xôi và tách biệt.
6. Xử lý ngôn ngữ một cách tự nhiên
Xử lý ngôn ngữ một cách tự nhiên (Natural Language Processing hay NLP) nằm trong lĩnh vực trí tuệ nhân tạo và các công việc phát triển giao tiếp giữa con người và máy vi tính.
Mục tiêu của NLP là đọc và giải mã ý nghĩa của ngôn ngữ con người. NLP phần lớn được dựa trên machine learning và nó được sử dụng để lập trình các ứng dụng xử lý từ ngữ và các phần mềm phiên dịch.
Các kỹ năng NLP cần có các thuật toán để nhận diện và thu thập các dữ liệu cần thiết từ mỗi câu bằng cách áp dụng các quy tắc ngữ pháp. Phân tích cú pháp và Phân tích ngữ nghĩa là các kỹ thuật chủ yếu được dùng trong NLP. Phân tích cú pháp xử lý câu và các vấn đề về ngữ pháp, trong khi phân tích ngữ nghĩa xử lý về ý nghĩa của dữ liệu/văn bản.
7. Đám mây hỗn hợp (Hybrid Clouds)
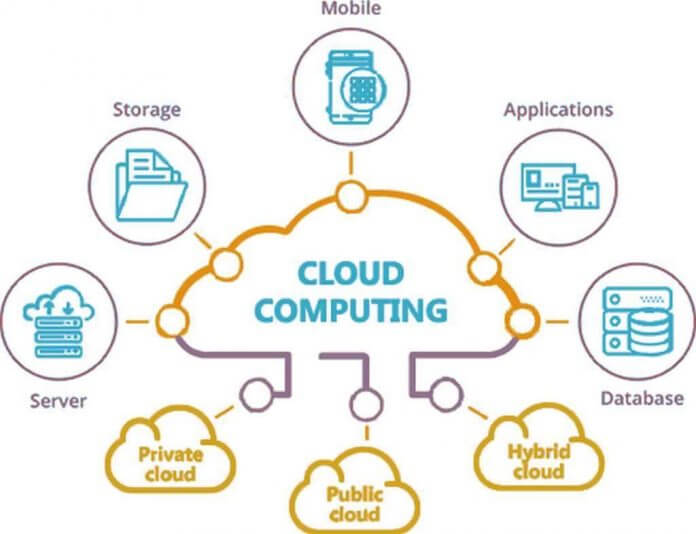
Là một hệ thống điện toán đám mây sử dụng các đám mây riêng lưu dữ liệu tại chỗ và một đám mây công khai của bên thứ ba và có sự điều hành giữa 2 giao diện. Đám mây hỗn hợp cung cấp sự linh hoạt và nhiều lựa chọn triển khai dữ liệu hơn bằng cách chuyển các quy trình xử lý qua lại giữa đám mây riêng và đám mây công khai.
Các tổ chức phải có một hệ thống đám mây riêng để có khả năng đáp ứng với các đám mây công cộng. Để làm được điều đó thì cần phải xây dựng các trung tâm dữ liệu, bao gồm máy chủ, kho lưu trữ, hệ thống mạng LAN, và hệ thống cân bằng tải.
Các tổ chức phải thiết lập các lớp ảo hóa/phần mềm siêu giám sát để hỗ trợ các máy ảo và các container. Và cuối cùng, cài đặt một lớp phần mềm đám mây riêng. Cài đặt phần mềm cho phép chuyển dữ liệu giữa đám mây riêng và đám mây công cộng
8. Dữ liệu tối (Dark Data)

Dữ liệu tối là dữ liệu mà một công ty không sử dụng trong bất kỳ các hệ thống phân tích nào. Các dữ lập được thu thập từ các trung tâm điều hành mạng mà không được dùng để chắt lọc insights hoặc dùng cho dự báo.
Các tổ chức có thể cho rằng đó là dữ liệu không chuẩn xác vì họ không thu lại được kết quả gì từ nó. Nhưng họ biết rằng dữ liệu đó vẫn rất quý giá. Với việc các dữ liệu tăng trưởng theo từng ngày, bất cứ ai cũng nên hiểu rằng những dữ liệu chưa được khám phá tiềm tàng rủi ro về an ninh. Sự tăng trưởng của Dữ liệu tối cũng được coi là một xu thế khác của Big data.
9. Cấu trúc dữ liệu (Data Fabric)
Cấu trúc dữ liệu là một kiến trúc và tập hợp của các mạng dữ liệu. Nó giúp cho khả năng vận hành đồng nhất trên các điểm cuối, cả trên phần mềm lưu dữ liệu tại chỗ và các môi trường đám mây.
Để thúc đẩy quá trình chuyển đổi số, Cấu trúc dữ liệu đơn giản hóa và kết hợp các kho dữ liệu trên khắp các hệ thống đám mây và các môi trường lưu dữ liệu tại chỗ, cho phép truy cập và chia sẻ dữ liệu trong một môi trường dữ liệu phân tán. Nó còn cung cấp một bộ khung quản lý dữ liệu nhất quán giữa các khó dữ liệu chưa được lưu trữ.
10. XOps
Là một ý tưởng kết hợp giữa Dữ liệu, Machine Learning, mô hình và các nền tảng. Mục tiêu của XOps là đạt năng suất và hiệu quả kinh tế dựa theo quy mô.
XOps đạt được bằng cách áp dụng các phương pháp tốt nhất của DevOps. Và từ đó đảm bảo về tính hiệu quả, có thể tái sử dụng và thực hiện lại trong khi giảm thiểu công nghệ, lặp quy trình và triển khai tự động hóa.
Những cải tiến này giúp điều chỉnh các sản phẩm mẫu với thiết kế linh hoạt và các hệ thống quản lý vận hành trơn tru.
Kết luận
Qua từng năm tháng, công nghệ Phân tích Big Data vẫn tiếp tục thay đổi. Vì vậy, Các doanh nghiệp cần đi theo đúng xu thế để vượt trội hơn so với các đối thủ cạnh tranh. Vậy, trên đây là những xu hướng công nghệ trong phân tích Big data trong năm 2022 và trong tương lai.
> Tham khảo thêm khóa Học Big Data ngay hôm nay!
---
HỌC VIỆN ĐÀO TẠO CNTT NIIT - ICT HÀ NỘI
Dạy học Lập trình chất lượng cao (Since 2002). Học làm Lập trình viên. Hành động ngay!
Đc: Tầng 3, 25T2, N05, Nguyễn Thị Thập, Cầu Giấy, Hà Nội
SĐT: 02435574074 - 0914939543 - 0353655150
Email: hello@niithanoi.edu.vn
Fanpage: https://facebook.com/NIIT.ICT/
#niit #niithanoi #niiticthanoi #hoclaptrinh #khoahoclaptrinh #hoclaptrinhjava #hoclaptrinhphp #java #python #php #bigdata