Big data ngày càng trở nên cần thiết trong cuộc sống. Nó đang trở thành ông hoàng trong thế giới CNTT. Vì thế việc trở thành big data developer đang là xu thế của thời đại
Tuy nhiên, làm thế nào để trở thành big data developer thì không phải ai cũng biết và dễ dàng đạt được. Để trở thành big data cần học gì hay để thành thạo big data cần học gì thì hãy tìm hiểu tại bài viết này
Top những kỹ năng cần có để trở thành big data developer
Trước tiên cùng đi tìm hiểu thế nào là big data developer, tổng quan về big data
Big data developer là gì?

Là người chịu trách nhiệm phát triển các ứng dụng Hadoop, phục vụ nhu cầu dữ liệu lớn của một tổ chức mà đang hoạt động với dữ liệu quá khổng lồ và cần được giải quyết
Nhà phát triển dữ liệu lớn (Big data developer) cần phải có đủ kỹ năng để quản lý toàn bộ vòng đời của giải pháp Hadoop bao gồm việc lựa chọn nền tảng, thiết kế kiến trúc kỹ thuật, phân tích các yêu cầu, phát triển ứng dụng và thiết kế, thử nghiệm và triển khai. Nói chung là mã hóa các dữ liệu Hadoop
Kỹ năng cần có của Big data developer
1. Kiến thức về Khung dữ liệu lớn hoặc các công nghệ dựa trên Hadoop.
Khối lượng dữ liệu ngày càng lớn lên đã sinh ra một khái niệm mới mang tên Hadoop. Hadoop chiếm ưu thế, trở thành nền tảng của các công nghệ dữ liệu lớn.
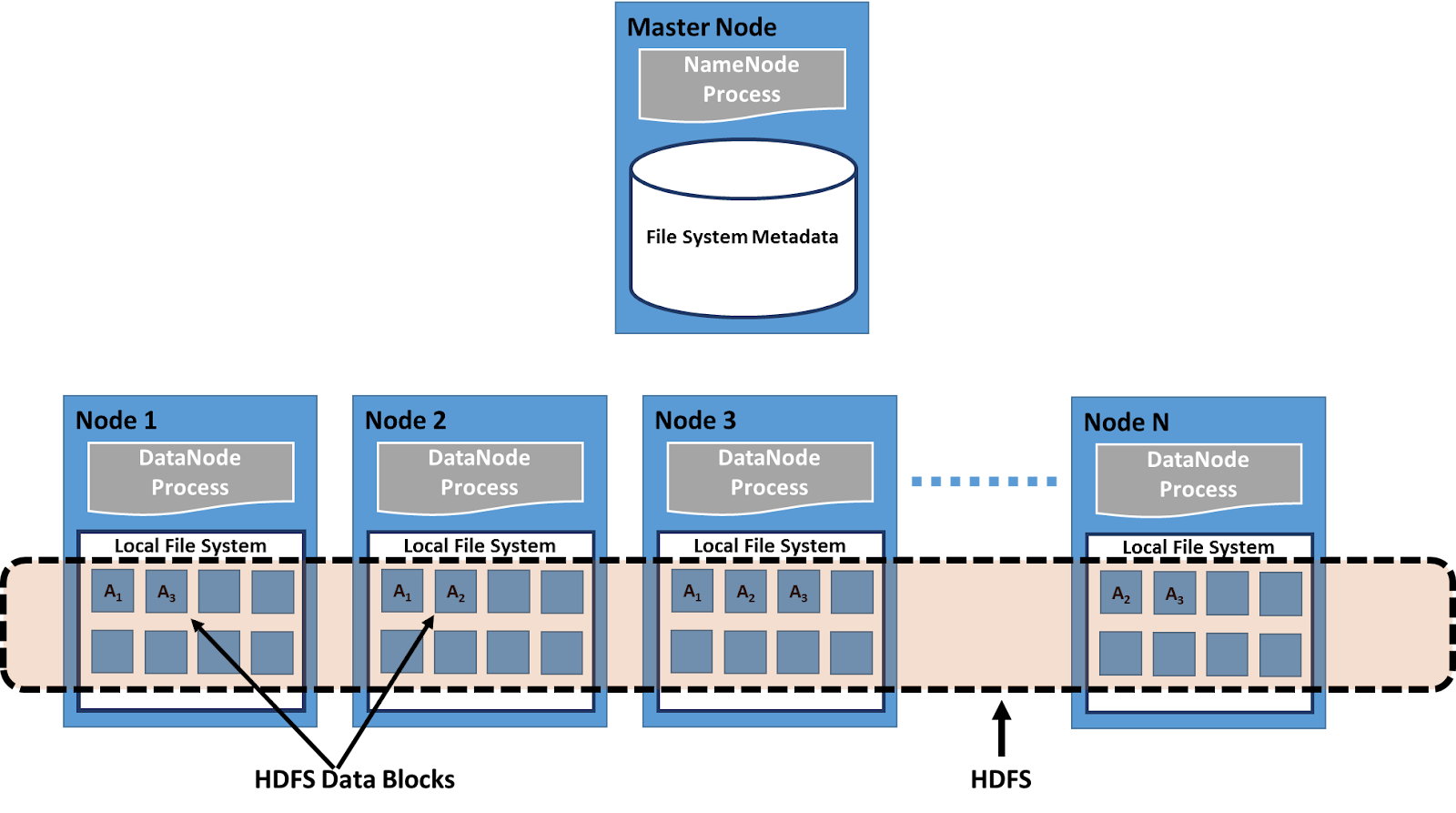
Để trở thành nhà phát triển dữ liệu bạn cần hiểu về Hadoop đầu tiên. Nó không phải là thuật ngữ đơn lẻ, nó là hệ sinh thái hoàn chỉnh, chứa một số công cụ phục vụ cho các mục đích khác nhau
Công cụ dữ liệu lớn với Hadoop cơ bản mà bạn cần nắm chắc đó là
1. HDFS (Hệ thống tệp phân tán Hadoop): HDFS là lớp lưu trữ trong Hadoop. Nó lưu trữ dữ liệu trên một cụm phần cứng hàng hóa. Trước khi học Hadoop, người ta nên có kiến thức về Hadoop HDFS vì nó là một trong những thành phần cốt lõi của khuôn khổ Hadoop.

2. YARN: Tuy nhiên, Người đàm phán tài nguyên khác (YARN) chịu trách nhiệm quản lý tài nguyên giữa các ứng dụng đang chạy trong cụm Hadoop. Nó thực hiện phân bổ tài nguyên và lập lịch công việc trong cụm Hadoop. Sự ra đời của YARN làm cho Hadoop linh hoạt hơn, hiệu quả hơn và có thể mở rộng.
3. MapReduce: MapReduce là trung tâm của khung công tác Hadoop. Nó là một khung xử lý song song cho phép dữ liệu được xử lý song song trên các cụm phần cứng rẻ tiền.
4. Hive: Hive là một công cụ lưu trữ dữ liệu mã nguồn mở được xây dựng dựa trên Hadoop. Với Hive, các nhà phát triển có thể thực hiện các truy vấn trên một lượng lớn dữ liệu được lưu trữ trong Hadoop HDFS.
5. Pig: Nó là một ngôn ngữ kịch bản cấp cao được sử dụng để chuyển đổi dữ liệu trên đỉnh Hadoop. Nó được các nhà nghiên cứu sử dụng để lập trình.
6. Flume: Flume là một công cụ phân tán, đáng tin cậy để nhập một lượng lớn dữ liệu phát trực tuyến như sự kiện, dữ liệu nhật ký, v.v. từ các máy chủ web khác nhau vào Hadoop HDFS.
7. Sqoop: Sqoop là một công cụ dữ liệu lớn được sử dụng để nhập và xuất dữ liệu từ các cơ sở dữ liệu quan hệ như MySQL, Oracle, v.v. sang Hadoop HDFS hoặc ngược lại.
8. ZooKeeper: Nó là một dịch vụ điều phối phân tán hoạt động như một người điều phối giữa các dịch vụ phân tán đang chạy trong cụm Hadoop. Nó chịu trách nhiệm quản lý và điều phối một cụm máy lớn.
9. Oozie: Oozie là một bộ lập lịch trình quy trình làm việc để quản lý các công việc Hadoop. Nó liên kết nhiều công việc thành một đơn vị công việc duy nhất và giúp hoàn thành một nhiệm vụ hoàn chỉnh.
2. Có kiến thức về khung xử lý thời gian thực (Apache Spark).
Xử lý thời gian thực với hành động nhanh chóng là nhu cầu của thế giới. Cho dù đó là hệ thống phát hiện gian lận hay hệ thống khuyến nghị, mỗi một trong số chúng đều yêu cầu xử lý thời gian thực. Đối với một nhà phát triển dữ liệu lớn, điều rất quan trọng là phải làm quen với khung xử lý thời gian thực.

Tổng quan về apache spark
Apache Spark là một khung xử lý phân tán thời gian thực với khả năng tính toán trong bộ nhớ. Vì vậy, Spark là lựa chọn tốt nhất cho các nhà phát triển dữ liệu lớn để có kỹ năng trong bất kỳ khuôn khổ xử lý thời gian thực nào.
3. Kiến thức về các công nghệ dựa trên SQL.
Ngôn ngữ truy vấn cấu trúc (SQL) là ngôn ngữ lấy dữ liệu làm trung tâm được sử dụng để cấu trúc, quản lý và xử lý dữ liệu có cấu trúc được lưu trữ trong cơ sở dữ liệu.
Vì SQL là nền tảng của kỷ nguyên dữ liệu lớn, do đó kiến thức về SQL là một lợi thế bổ sung cho các lập trình viên khi làm việc trên các công nghệ dữ liệu lớn. PL / SQL cũng được sử dụng rộng rãi trong ngành.
4. Có kiến thức về các công nghệ dựa trên NoSQL như MongoDB, Cassandra, HBase.
Các tổ chức đang tạo ra dữ liệu với tốc độ nhanh chóng. Số lượng dữ liệu đã phát triển ngoài sức tưởng tượng của chúng tôi. Các yêu cầu của các tổ chức hiện được mở rộng từ dữ liệu có cấu trúc sang phi cấu trúc.
Để đáp ứng yêu cầu ngày càng cao của các tổ chức, cơ sở dữ liệu NoSQL đã được giới thiệu. Cơ sở dữ liệu NoSQL có thể lưu trữ và quản lý một lượng lớn cấu trúc, dữ liệu bán cấu trúc và phi cấu trúc.
Một số cơ sở dữ liệu NoSQL được sử dụng nổi bật là:
1. Cassandra: Cassandra là một cơ sở dữ liệu NoSQL cung cấp khả năng mở rộng và tính sẵn sàng cao mà không ảnh hưởng đến hiệu suất. Nó là một nền tảng hoàn hảo cho dữ liệu quan trọng. Cassandra cung cấp khả năng đọc / ghi ngẫu nhiên và nhanh chóng. Nó cung cấp Tính khả dụng và Phân vùng ngoài CAP.
2. HBase: HBase là cơ sở dữ liệu NoSQL hướng cột được xây dựng trên Hadoop HDFS. Nó cung cấp quyền truy cập đọc hoặc ghi ngẫu nhiên theo thời gian thực nhanh chóng vào dữ liệu được lưu trữ trong Hệ thống tệp Hadoop. HBase cung cấp Tính nhất quán và Phân vùng ngoài CAP (Tính nhất quán, Tính khả dụng và Phân vùng).
3. MongoDB: MongoDB là một cơ sở dữ liệu NoSQL hướng tài liệu có mục đích chung. Đây là một cơ sở dữ liệu NoSQL cung cấp tính khả dụng cao, khả năng mở rộng và hiệu suất cao. MongoDB cung cấp tính nhất quán và phân vùng ra khỏi CAP.
Một chuyên gia có kiến thức về cơ sở dữ liệu NoSQL sẽ không bao giờ lỗi thời.
5. Kiến thức về bất kỳ ngôn ngữ lập trình nào (Java / Python / R).
Để trở thành một nhà phát triển Dữ liệu lớn, bạn phải có kỹ năng viết mã tốt. Bạn phải có kiến thức về cấu trúc dữ liệu, thuật toán và ít nhất một ngôn ngữ lập trình.
Có nhiều ngôn ngữ lập trình khác nhau như Java, R, Python, Scala, v.v. phục vụ cho các mục đích giống nhau. Tất cả các ngôn ngữ lập trình có cú pháp khác nhau nhưng logic vẫn giống nhau.
Đối với người mới bắt đầu, tôi khuyên bạn nên sử dụng Python vì nó rất dễ học và là một ngôn ngữ thống kê.
6. Có kiến thức về các công cụ trực quan như Tableau, QlikView, QlikSense.
Các chuyên gia dữ liệu lớn phải có khả năng giải thích dữ liệu bằng cách trực quan hóa nó. Điều này đòi hỏi lợi thế về toán học và khoa học để có thể dễ dàng hiểu được dữ liệu lớn phức tạp bằng sự sáng tạo và trí tưởng tượng.
Có một số công cụ trực quan hóa dữ liệu nổi bật như QlikView, Tableau, Qlik Sense giúp hiểu được phân tích được thực hiện bởi các công cụ phân tích khác nhau. Học các công cụ trực quan hóa thêm một lợi thế cho bạn nếu bạn muốn nâng cao kỹ năng phân tích dữ liệu và hình ảnh hóa của mình.
7. Kiến thức về các công cụ Khai thác dữ liệu khác nhau như Rapidminer, KNIME, v.v.
Khai thác dữ liệu rất quan trọng khi chúng ta nói về việc trích xuất, lưu trữ và xử lý một lượng lớn dữ liệu. Để làm việc với công nghệ dữ liệu lớn, bạn phải quen thuộc với các công cụ khai thác dữ liệu như Apache Mahout, Rapid Miner, KNIME, v.v.
8. Kiến thức về thuật toán học Máy.
Học máy là lĩnh vực nóng nhất của dữ liệu lớn. ML giúp phát triển các hệ thống khuyến nghị, cá nhân hóa và phân loại.
Để trở thành một nhà phân tích dữ liệu thành công, người ta cần phải nắm vững các thuật toán học máy.
9. Kiến thức về Phân tích thống kê & định lượng.
Dữ liệu lớn là tất cả về chữ số. Phân tích định lượng và thống kê là phần quan trọng nhất của phân tích dữ liệu lớn.
Kiến thức về thống kê và toán học giúp hiểu các khái niệm cốt lõi như phân phối xác suất, thống kê tóm tắt, biến ngẫu nhiên, phân phối xác suất. Kiến thức về các công cụ khác nhau như R, SAS, SPSS, v.v. khiến bạn khác biệt với những người khác đang đứng trong hàng đợi.
10. Tự do trên Linux hoặc Unix hoặc Solaris hoặc MS-Windows.
Các hệ điều hành khác nhau được sử dụng bởi nhiều ngành công nghiệp. Unix và Linux là những hệ điều hành được sử dụng nhiều nhất. Nhà phát triển dữ liệu lớn cần phải thành thạo ít nhất một trong số chúng.
11. Phải sở hữu khả năng giải quyết vấn đề và tư duy sáng tạo.
Bạn phải có khả năng giải quyết vấn đề và óc sáng tạo khi làm việc trong bất kỳ lĩnh vực nào. Việc triển khai các kỹ thuật dữ liệu lớn khác nhau cho các giải pháp hiệu quả cần cả hai phẩm chất này ở các chuyên gia.
12. Phải có Kiến thức Kinh doanh.
Để làm việc trong một miền, một trong những kỹ năng quan trọng nhất là kiến thức về miền mà anh ta đang làm việc. Để phân tích bất kỳ dữ liệu nào hoặc phát triển bất kỳ ứng dụng nào, người ta phải có kiến thức kinh doanh để phân tích hoặc phát triển có lợi.
Tổng kết: Nhìn chung, để trở thành chuyên gia trong big data thì bạn cần nắm tối thiểu 6 kỹ năng kể trên. Chúc bạn rèn luyện thành công trên con đường trở thành nhà phát triển dữ liệu lớn